
Predicting football player values

Introduction
Ever thought some football players are seriously overvalued or that your favourite player in the lower leagues is underrated?
I recently came across a fantastically data-rich website called sofifa.com. It has data on every football player in each professional football league around the world, including their playing attributes, value, position, wage, preferred foot, team, country, contract length, weight….. the list is pretty endless.
I had been looking for some dataset to practice regression modelling techniques and this looked perfect. Most people use the famous Boston housing data set for this purpose, but I have lost count of the number of blog posts repeating the same analysis and repeating the same results (😴) so thought it would be more interesting to curate my own dataset - this also provided an excellent excuse to write a webscraper to collect the data (one of my favourite pastimes🙈).
After collecting the data (webscraper here),I set about inspecting the dataset features and creating a model to predict the value of each player. There were three main questions I wanted to answer:
- Can the value of a football player be predicted from their playing attributes and meta data?
- Which factors are most important for determining a player’s market value?
- Which players are over or undervalued compared to the market?
This information could be beneficial for two main reasons:
- Football teams/scouts can identify whether a target player is currently over or undervalued and what price they should be willing to pay for a player of that quality (regardless of current form)
- Understanding which factors most affect value could inform up and coming players which skills are most in demand in the market and which skills they should focus on improving to increase their value.
Below is an executive summary of the findings of the regression analysis.
Full code and notebook is available on Github
To view the Jupyter notebook in nbviewer click here
Analysis Summary
Information about each professional football player, such as attribute scores (e.g. passing, accuracy, stamina, acceleration etc.) and additional information (e.g. age, position, potential etc.), was collected from the SoFIFA website for the 2019 season. This information was used to develop a model to predict the value of each player.
The distribution of player market values is very positively skewed with most players having relatively low valuations (< €1M), but with a few exceptional players commanding a significant premium. This variable was log transformed to normalize the data and create the target variable for modelling - log(value).
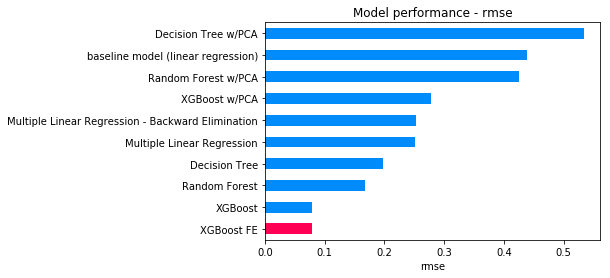
Initially, six regression models were tested on the full set of features (linear regression, multiple linear regression, decision trees, random forests and XGBoost) using GridSearchCV to tune the hyper-parameters. XGBoost performed the best with a root mean squared error (RMSE) of 0.18. After interpreting the model output, individual playing attributes were found to be statistically significant but not economically significant. The playing attributes were combined into more general categories to reduce the model complexity but preserve some of the information contained in these features. Using the XGBoost algorithm on the new feature set, the performance of the model was marginally improved, yielding a RMSE of 0.17.
| rmse | adj. r2 | |
|---|---|---|
| XGBoost FE | 0.078654 | 0.996748 |
| XGBoost | 0.079354 | 0.996672 |
| Random Forest | 0.167902 | 0.985099 |
| Decision Tree | 0.197168 | 0.979451 |
| Multiple Linear Regression | 0.250560 | 0.967403 |
| Multiple Linear Regression - Backward Elimination | 0.252326 | 0.967028 |
| XGBoost w/PCA | 0.278596 | 0.958974 |
| Random Forest w/PCA | 0.425746 | 0.904190 |
| baseline model (linear regression) | 0.438973 | 0.900383 |
| Decision Tree w/PCA | 0.533455 | 0.849580 |
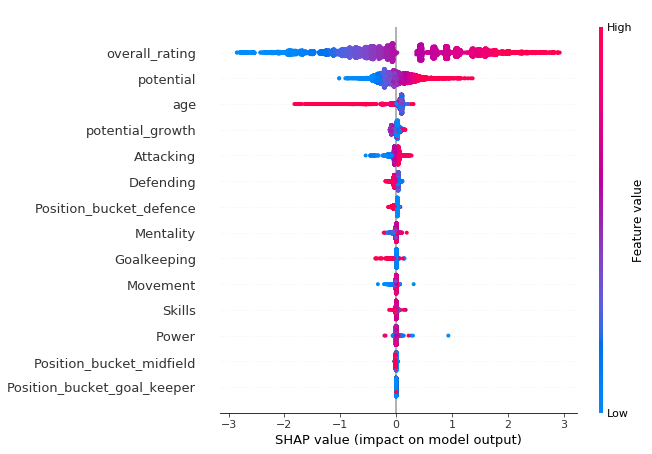
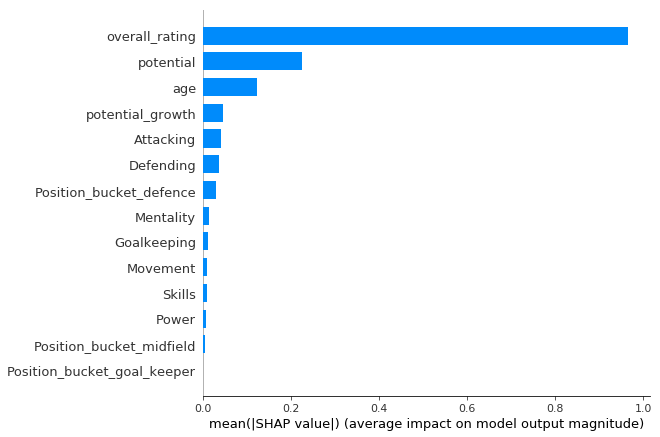
SHAP values were used to interpret the XGBoost model with overall rating, player potential and age found to be the most important features. Age had a non-linear relationship with the target variable with older players having a significantly lower predicted market value. Of the skills features, attacking skills (Crossing, finishing, short passing etc.) were the most important for increasing the predicted value.
The model was used to identify under and overvalued English players. The overvalued players included relatively famous names and/or players who had played for big clubs in the past. This suggests that popularity/reputation, which was not included as a feature, could inflate the value of players above their fundamental skill.
Top 10 overvalued players from England
| name | country | age | overall_rating | Position | value_clean | predicted_value | difference | difference_pct | |
|---|---|---|---|---|---|---|---|---|---|
| 6206 | Dean Marney | England | 34 | 67 | midfield | 375000.0 | 2.809261e+05 | 9.407391e+04 | 25.086375 |
| 12116 | David Perkins | England | 36 | 65 | midfield | 170000.0 | 1.299228e+05 | 4.007724e+04 | 23.574848 |
| 1600 | Adebayo Akinfenwa | England | 36 | 66 | attack | 230000.0 | 1.880056e+05 | 4.199441e+04 | 18.258437 |
| 9161 | Matt Bloomfield | England | 34 | 63 | midfield | 180000.0 | 1.494351e+05 | 3.056489e+04 | 16.980495 |
| 12245 | Christopher Hamilton | England | 23 | 66 | defence | 925000.0 | 7.827488e+05 | 1.422512e+05 | 15.378507 |
| 5745 | Jack Cork | England | 29 | 76 | midfield | 7500000.0 | 6.386116e+06 | 1.113884e+06 | 14.851793 |
| 12855 | Tommy Rowe | England | 29 | 67 | midfield | 750000.0 | 6.433922e+05 | 1.066078e+05 | 14.214367 |
| 9205 | Darren Pratley | England | 33 | 66 | midfield | 375000.0 | 3.225915e+05 | 5.240850e+04 | 13.975600 |
| 7652 | Jabo Ibehre | England | 35 | 59 | attack | 70000.0 | 6.067787e+04 | 9.322133e+03 | 13.317333 |
| 5331 | Levi Sutton | England | 21 | 60 | defence | 290000.0 | 2.520315e+05 | 3.796853e+04 | 13.092597 |
Top 10 undervalued players from England
| name | country | age | overall_rating | Position | value_clean | predicted_value | difference | difference_pct | |
|---|---|---|---|---|---|---|---|---|---|
| 9168 | Gary O'Neil | England | 35 | 67 | midfield | 180000.0 | 2.733090e+05 | -93308.96875 | -51.838316 |
| 13103 | Matty Blair | England | 29 | 65 | midfield | 400000.0 | 4.881799e+05 | -88179.87500 | -22.044969 |
| 7650 | Karl Henry | England | 35 | 67 | midfield | 180000.0 | 2.159892e+05 | -35989.21875 | -19.994010 |
| 12202 | Gareth Barry | England | 37 | 72 | midfield | 425000.0 | 5.048729e+05 | -79872.87500 | -18.793618 |
| 2263 | Luke O'Nien | England | 23 | 66 | midfield | 750000.0 | 8.740792e+05 | -124079.25000 | -16.543900 |
| 11344 | Harry Pell | England | 26 | 66 | midfield | 625000.0 | 7.240376e+05 | -99037.56250 | -15.846010 |
| 8471 | Tom Hateley | England | 28 | 68 | midfield | 725000.0 | 8.392409e+05 | -114240.87500 | -15.757362 |
| 12891 | George Francomb | England | 26 | 63 | midfield | 325000.0 | 3.742320e+05 | -49231.96875 | -15.148298 |
| 6714 | Nathan Byrne | England | 26 | 69 | midfield | 1000000.0 | 1.150460e+06 | -150459.75000 | -15.045975 |
| 10568 | James Horsfield | England | 22 | 63 | midfield | 400000.0 | 4.576239e+05 | -57623.90625 | -14.405977 |
Future Work
- expose the machine learning model to a user interface (e.g. webapp (dash or streamlit) so that the user can input their own data and get a prediction for the value of a player with those attributes
- incorporate different features into the model such as current league/country or commercial factors such as social media following and brand appeal
- link the value of each player to their on pitch performance (e.g. number of career goals/clean sheets, number of goals last season etc.)
- collect data from different time periods to predict which players are likely to increase in value and what factors are most predictive
- from example, collect data from 2/3 years ago and compare how the values of each football player (still playing) has changed.
Resources
Data
- Original data scraped from the SOFIFA website
- see data_collection folder in repository for scraper - note that it may not work if the website layout has been changed
Articles
- Managing machine learning workflows - Matthew Mayo, KDnuggets
- Interpretable Machine Learning - Scott Lundberg, TowardsDataScience
- Shap-values - Kaggle
- Decision tree regressor explained - George Drakos
- Feature selection techniques - Gabriel Azevedo, TowardsDataScience
- Machine Learning data pipelines - TowardsDataScience
Comments