
Visualising asset price correlations
⚠️ Please see updated and improved article on my new blog - Engineering for Data Science
Topics covered
- Calculating correlations between asset classes
- Heatmap visualisation using seaborn
- Network analysis and visualisation using Networkx
- Minimum spanning trees
- Interactive visualisations using Plotly
All code and raw data is available in this Github repository
The final interactive Plotly visualisation is embedded at the bottom of this page ( here )
Introduction
Network analysis is becoming an ever increasingly popular method to analyse and visualise complex relationships in data in an intuitive way.
One interesting application of network analytics is visualising relationships between asset classes in the finance industry. We are always told that equities and bonds tend to move in opposite directions and certain assets such as gold and the Japanese Yen are ‘safe-haven’ assets and therefore behave in similar ways. But what does that actually look like and are there any other interesting relationships between asset classes? Networks can be a great way to convey this information at a high level and help understand broad market dynamics.
Information on the correlations between asset classes can be particularly useful for investors wanting to diversify their portfolio. Most people understand that portfolio risk can be mitigated by diversification, however, this may not always be the case. For instance if you ‘diversified’ your portfolio by investing in two different stocks which are strongly correlated with each other (i.e. if stock A goes up 2% then stock B also goes up 2%) then the overall risk of the portfolio has not been reduced as if there is a negative factor affecting stock A then it is also likely to affect stock B and both prices will trend downwards. Therefore, diversification can only be realistically achieved by investing in assets which are uncorrelated with each other. Good explanations of this phenomenon can be found at Quantdare and the Investors Chronicle.
In this post I will explain how we can visualise asset correlations as an interactive network diagram which allows the user to gain a high level overview of the relationships between asset classes. From this information they can identify areas of risk but also opportunities for diversification of their portfolio. We will cover the basics of how to calculate correlations between asset price returns using numpy and pandas, using networkx to create a network graph and finally use Plotly to display the network as an interactive visualisation.
Library imports
- numpy and pandas to read and manipulate the raw data
- networkx to generate the network representation of the data and create some initial graph visualisations
- matplotlib and seaborn for general visualisations and plot formatting
- Plotly to create the final interactive visualisation
Load data
For this analysis I will use a dataset containing the daily adjusted closing prices of 39 major ETFs which represent different asset classes covering equities, bonds, currencies and commodities. The data covers a period of 4 years between November 2013 and November 2017.
There are 1013 rows and 39 columns in the dataset
Data timeperiod covers: 2013-11-01 to 2017-11-08
| EOD~BND.11 | EOD~DBC.11 | EOD~DIA.11 | EOD~EEM.11 | EOD~EFA.11 | EOD~EMB.11 | EOD~EPP.11 | EOD~EWG.11 | EOD~EWI.11 | EOD~EWJ.11 | ... | EOD~VGK.11 | EOD~VPL.11 | EOD~VXX.11 | EOD~XLB.11 | EOD~XLE.11 | EOD~XLF.11 | EOD~XLK.11 | EOD~XLU.11 | EOD~CSJ.11 | EOD~FXF.11 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Date | |||||||||||||||||||||
| 2017-11-08 | 81.83 | 16.40 | 235.46 | 46.78 | 69.87 | 114.60 | 47.69 | 33.18 | 30.95 | 60.02 | ... | 58.20 | 72.77 | 33.53 | 58.70 | 69.82 | 26.25 | 64.01 | 55.70 | 104.96 | 94.5100 |
| 2017-11-07 | 81.89 | 16.43 | 235.42 | 46.56 | 69.64 | 114.65 | 47.22 | 33.07 | 31.09 | 59.65 | ... | 58.17 | 72.20 | 33.52 | 58.64 | 70.16 | 26.38 | 63.66 | 55.66 | 105.01 | 94.5400 |
| 2017-11-06 | 81.86 | 16.53 | 235.41 | 46.86 | 69.90 | 115.26 | 47.20 | 33.34 | 31.22 | 59.18 | ... | 58.67 | 71.98 | 33.34 | 58.58 | 70.25 | 26.75 | 63.63 | 55.00 | 105.00 | 94.7500 |
| 2017-11-03 | 81.80 | 16.22 | 235.18 | 46.34 | 69.80 | 115.42 | 47.09 | 33.39 | 31.22 | 59.19 | ... | 58.58 | 71.88 | 33.66 | 58.83 | 68.68 | 26.78 | 63.49 | 55.21 | 105.00 | 94.4400 |
| 2017-11-02 | 81.73 | 16.12 | 234.96 | 46.58 | 69.91 | 116.15 | 47.31 | 33.50 | 31.43 | 59.05 | ... | 58.69 | 71.89 | 33.71 | 58.86 | 68.48 | 26.89 | 62.99 | 55.01 | 105.04 | 94.6299 |
5 rows × 39 columns
We can see that the csv file of asset prices contains 39 different assets and 1013 records for each asset. The time-series is in reverse order (newest to oldest) and there are no missing datapoints in the dataset. Each ETF in the dataset is encoded by its abbreviated ticker which makes it difficult to understand what sector each ETF actually represents. To make the ETF codes more readable I created an alias for each one which is more descriptive. We will rename the columns with these aliases so the future analysis is more interpretable.
| Code | ETF Alias | |
|---|---|---|
| 0 | EOD~BND.11 | Bonds Global |
| 1 | EOD~DBC.11 | Commodities |
| 2 | EOD~DIA.11 | DOW |
| 3 | EOD~EEM.11 | Emerg Markets |
| 4 | EOD~EFA.11 | EAFE ETF |
| 5 | EOD~EMB.11 | Emerg Markets Bonds |
| 6 | EOD~EPP.11 | Pacifix ex Japan |
| 7 | EOD~EWG.11 | Germany |
| 8 | EOD~EWI.11 | Italy |
| 9 | EOD~EWJ.11 | Japan |
| 10 | EOD~EWQ.11 | France |
| 11 | EOD~EWU.11 | UK |
| 12 | EOD~FXB.11 | GBP |
| 13 | EOD~FXC.11 | China Large Cap |
| 14 | EOD~FXE.11 | Euro |
| 15 | EOD~FXI.11 | China |
| 16 | EOD~FXY.11 | Yen |
| 17 | EOD~GDX.11 | Gold Miners |
| 18 | EOD~GLD.11 | Gold |
| 19 | EOD~IEF.11 | 10yr treasuries |
| 20 | EOD~IYR.11 | US real estate |
| 21 | EOD~JNK.11 | High yield Bond |
| 22 | EOD~LQD.11 | Corp Bond |
| 23 | EOD~SLV.11 | Silver |
| 24 | EOD~SPY.11 | SNP 500 ETF |
| 25 | EOD~TIP.11 | Bonds II |
| 26 | EOD~TLT.11 | 20+ Treasuries |
| 27 | EOD~USO.11 | Oil |
| 28 | EOD~UUP.11 | USD |
| 29 | EOD~VGK.11 | Europe |
| 30 | EOD~VPL.11 | Pacific |
| 31 | EOD~VXX.11 | VXX |
| 32 | EOD~XLB.11 | Materials |
| 33 | EOD~XLE.11 | Energy |
| 34 | EOD~XLF.11 | Finance |
| 35 | EOD~XLK.11 | Tech |
| 36 | EOD~XLU.11 | Utilities |
| 37 | EOD~CSJ.11 | ST Corp Bond |
| 38 | EOD~FXF.11 | CHF |
Calculate asset price correlations
Convert to log returns
Before calculating the correlation matrix, it is important to first normalise the dataset and convert the absolute asset prices into daily returns. In financial time-series it is common to make this transformation as investors are typically interested in returns on assets rather than their absolute prices. By normalising the data it allows us to compare the expected returns of two assets more easily.
| Bonds Global | Commodities | DOW | Emerg Markets | EAFE ETF | Emerg Markets Bonds | Pacifix ex Japan | Germany | Italy | Japan | ... | Europe | Pacific | VXX | Materials | Energy | Finance | Tech | Utilities | ST Corp Bond | CHF | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Date | |||||||||||||||||||||
| 2017-11-08 | -0.000733 | -0.001828 | 0.000170 | 0.004714 | 0.003297 | -0.000436 | 0.009904 | 0.003321 | -0.004513 | 0.006184 | ... | 0.000516 | 0.007864 | 0.000298 | 0.001023 | -0.004858 | -0.004940 | 0.005483 | 0.000718 | -0.000476 | -0.000317 |
| 2017-11-07 | 0.000366 | -0.006068 | 0.000042 | -0.006423 | -0.003727 | -0.005306 | 0.000424 | -0.008131 | -0.004173 | 0.007911 | ... | -0.008559 | 0.003052 | 0.005384 | 0.001024 | -0.001282 | -0.013928 | 0.000471 | 0.011929 | 0.000095 | -0.002219 |
| 2017-11-06 | 0.000733 | 0.018932 | 0.000977 | 0.011159 | 0.001432 | -0.001387 | 0.002333 | -0.001499 | 0.000000 | -0.000169 | ... | 0.001535 | 0.001390 | -0.009552 | -0.004259 | 0.022602 | -0.001121 | 0.002203 | -0.003811 | 0.000000 | 0.003277 |
| 2017-11-03 | 0.000856 | 0.006184 | 0.000936 | -0.005166 | -0.001575 | -0.006305 | -0.004661 | -0.003289 | -0.006704 | 0.002368 | ... | -0.001876 | -0.000139 | -0.001484 | -0.000510 | 0.002916 | -0.004099 | 0.007906 | 0.003629 | -0.000381 | -0.002009 |
| 2017-11-02 | 0.000979 | 0.006223 | 0.003283 | 0.001289 | 0.003008 | 0.002759 | 0.005723 | 0.004488 | 0.009591 | 0.001186 | ... | 0.002559 | 0.002089 | -0.011210 | -0.007279 | -0.002916 | 0.009341 | 0.000476 | 0.003642 | 0.000000 | 0.004553 |
5 rows × 39 columns
Calculate correlations matrix
To calculate the pairwise correlations between assets we can simply use the inbuilt pandas corr() function.
| Bonds Global | Commodities | DOW | Emerg Markets | EAFE ETF | Emerg Markets Bonds | Pacifix ex Japan | Germany | Italy | Japan | ... | Europe | Pacific | VXX | Materials | Energy | Finance | Tech | Utilities | ST Corp Bond | CHF | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Bonds Global | 1.000000 | -0.086234 | -0.279161 | -0.069623 | -0.177521 | 0.296679 | -0.104739 | -0.188547 | -0.201014 | -0.159231 | ... | -0.181249 | -0.141707 | 0.222886 | -0.220603 | -0.198536 | -0.420264 | -0.197672 | 0.301774 | 0.598105 | 0.250142 |
| Commodities | -0.086234 | 1.000000 | 0.305137 | 0.428909 | 0.369637 | 0.313791 | 0.400316 | 0.283711 | 0.331083 | 0.250509 | ... | 0.367019 | 0.341089 | -0.224835 | 0.429541 | 0.677430 | 0.257454 | 0.225463 | 0.089290 | 0.028872 | 0.042324 |
| DOW | -0.279161 | 0.305137 | 1.000000 | 0.719260 | 0.793387 | 0.343817 | 0.688344 | 0.722882 | 0.666315 | 0.691672 | ... | 0.765251 | 0.769604 | -0.797538 | 0.817422 | 0.655544 | 0.874902 | 0.849271 | 0.395247 | -0.042967 | -0.172730 |
| Emerg Markets | -0.069623 | 0.428909 | 0.719260 | 1.000000 | 0.796425 | 0.580454 | 0.815049 | 0.697222 | 0.660268 | 0.638955 | ... | 0.763111 | 0.811155 | -0.668680 | 0.674630 | 0.607172 | 0.606749 | 0.686458 | 0.365031 | 0.123624 | -0.018461 |
| EAFE ETF | -0.177521 | 0.369637 | 0.793387 | 0.796425 | 1.000000 | 0.466883 | 0.790699 | 0.884385 | 0.830052 | 0.785198 | ... | 0.949368 | 0.872972 | -0.721559 | 0.720030 | 0.610561 | 0.711714 | 0.725415 | 0.352270 | 0.050121 | 0.021760 |
5 rows × 39 columns
Correlations Heatmap
The conventional way to visualise correlations is via a heatmap. Before developing the network visualisation, we will quickly create a heatmap of the correlation matrix to check the output of the correlation calculations and to gain a high level insight into some of the relationships present in the data.
Seaborn has a very useful function called clustermap which visualises the matrix as a heatmap but also clusters the ETFs so that ETFs which behave similarly are next to each other. Clustered heatmaps can be a useful way of visualising correlations between attributes in a dataset, especially if the data is highly dimensional as it automatically reorders attributes which are similar to each other into clusters. This makes the heatmap more structured and readable so it is easier to identify relationships between ETFs and which asset classes behave similarly.
Clustered Heatmap: Correlations between asset price returns
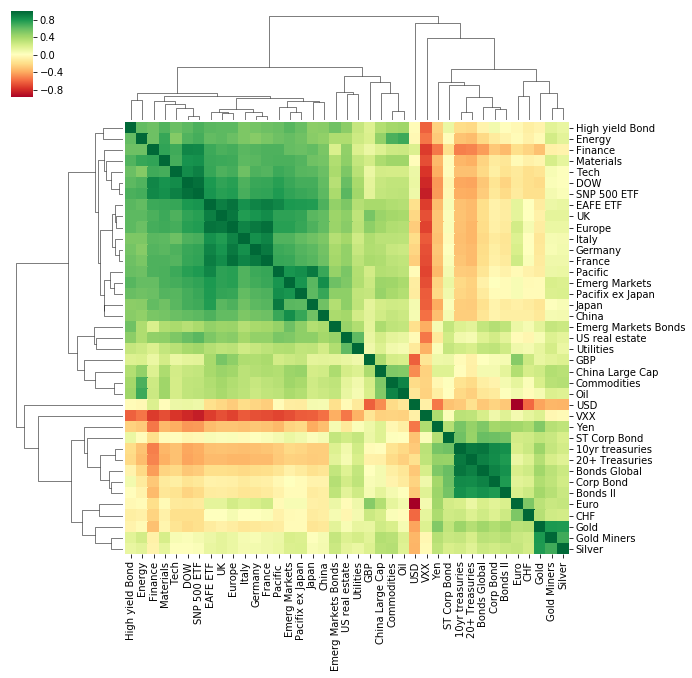
The heatmap is colour coded using a divergent colourscale where strong positive correlations (correlation = 1) are dark green, uncorrelated assets are yellow (correlation = 0) and negatively correlated assets are red (correlation = -1).
The clustered heatmap visualisation already gives a good picture of the data and tells an interesting story:
- Broadly speaking, there are two major clusters of assets. These appear to be separated into equities and “non-equity” assets (e.g. bonds, currencies and precious metals). The heatmap shows that these two categories are generally negatively or non-correlated with each other which is expected as ‘safe haven’ assets such as bonds, gold and currencies like the Japanese Yen tend to move in opposite directions to equities which are seen as a riskier asset class.
- ETFs tracking Geographic regions which are close to each other are highly correlated with each other. For example, UK, Europe, Germany, Italy and France ETFs are highly correlated with each other, so are Japan, Pacific ex Japan and China ETFs
- The VXX ETF is strongly negatively correlated with equities.
Network Visualisations
Heatmaps are useful, however, they can only convey one dimension of information (the magnitude of the correlation between two assets). As an investor wanting to make a decision on which asset classes to invest in, a heatmap still does not help answer important questions such as what the annualized returns and volatility of an asset class is.
We can use network graphs to investigate the initial findings from the heatmap further and visualise them in a more accessible way which encodes more information.
Networkx
Networkx is one of the most popular and useful Python libraries for analysing small/medium size networks.
In order to analyse the the correlations matrix as a network we first need to convert the correlations between assets to an edge list. This is a list containing information for each connection between each asset ETF in our data. This format requires the ‘source’ node (ETF), the ‘target’ node and the ‘weight’ (correlation) of the link between the two.
Create edge list
| asset_1 | asset_2 | correlation | |
|---|---|---|---|
| 1 | Bonds Global | Commodities | -0.086234 |
| 2 | Bonds Global | DOW | -0.279161 |
| 3 | Bonds Global | Emerg Markets | -0.069623 |
| 4 | Bonds Global | EAFE ETF | -0.177521 |
| 5 | Bonds Global | Emerg Markets Bonds | 0.296679 |
Create graph from edge list
Now that we have an edge list we need to feed that into the networkx library to create a graph. Note that this network is undirected as the correlation between assets is the same in both directions.
Name:
Type: Graph
Number of nodes: 39
Number of edges: 741
Average degree: 38.0000
Visualise the network
To visualise the graph we have just created, we can use a number of ‘out-of-the-box’ layouts which can be drawn using networkx, for example:
- circular_layout - Position nodes on a circle.
- random_layout - Position nodes uniformly at random in the unit square.
- spectral_layout - Position nodes using the eigenvectors of the graph Laplacian.
- spring_layout - Position nodes using Fruchterman-Reingold force-directed algorithm.
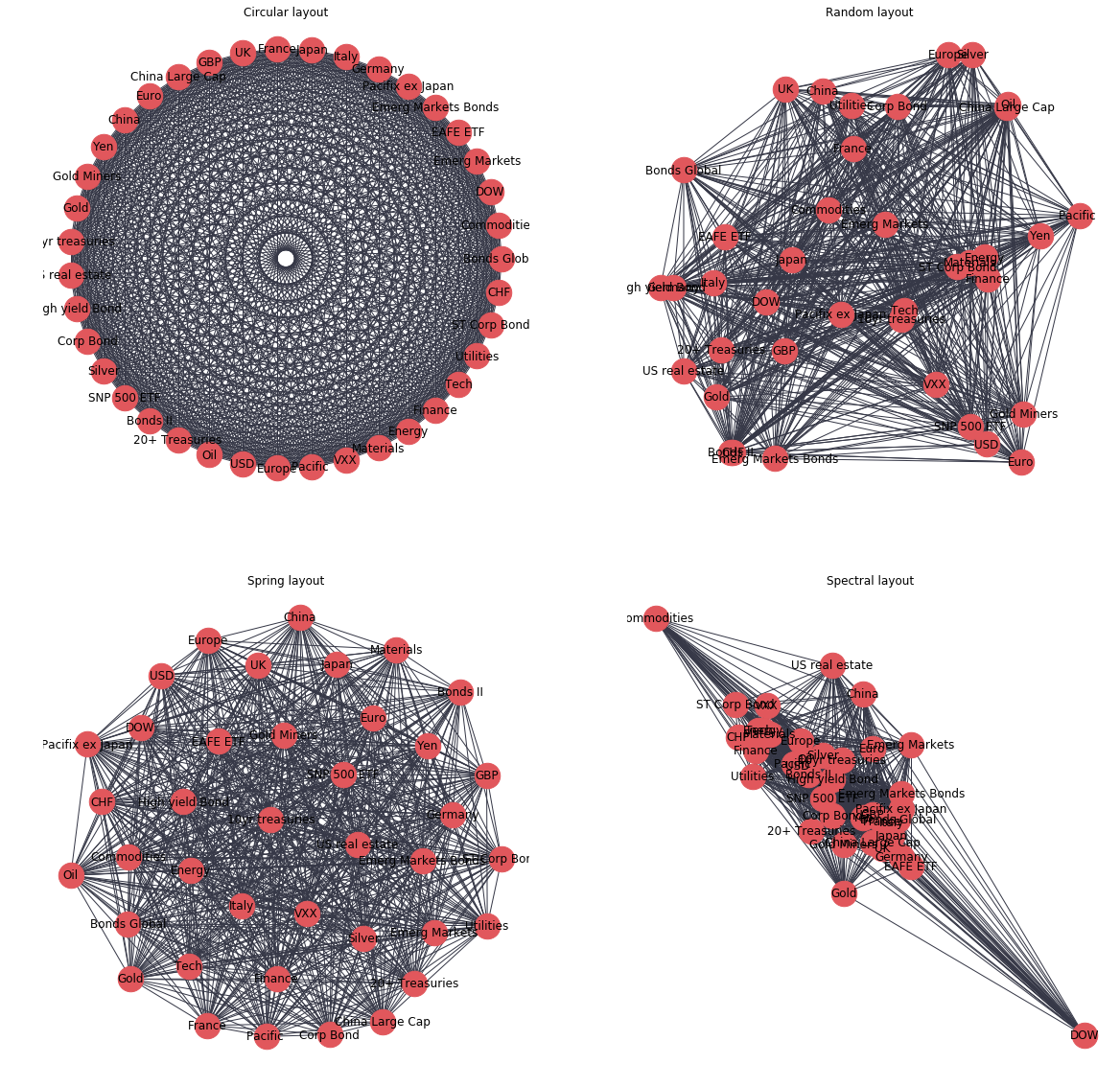
Whilst these visualisations may look pretty, they are not very useful in their current form as all nodes have the same number of edges (links), and each edge looks the same so no useful information about the correlations between ETFs can be gained.
Improved network visualisation
The network visualisation can be improved in a number of ways by thinking about the sort of information which we are looking to uncover from this analysis. It is important to think about what questions we wish to answer from the data and then design the visualisation to gain the most insight for the question in hand. For the purposes of enhancing the visualisation, We will assume that the audience for this visualisation will be investors wanting to assess risk in their portfolio. Investors would want to identify which assets are correlated and uncorrelated with each other in order to assess the unsystematic risk in their portfolio. Therefore, from this visualisation the user would want to quickly understand:
- which assets show strong/meaningful correlations (i.e. >0.5) with each other
- are these correlations positive or negative
- which are the most/least ‘connected’ assets. (i.e. which assets share the most/least strong correlations with other assets in the dataset)
- which groups of assets behave similarly (i.e. which assets are correlated with the same type of other assets)
With this information, an investor could identify if they held a number of assets which behave the same (increased risk) and identify assets which show very few correlations with assets currently held in the portfolio and investigate these as a potential opportunity for diversification.
For a first iteration to improve the network visualisation we can take the circular layout graph from above and make the following changes:
- reduce the number of connections between nodes by adding a threshold value for the strength of correlation
- introduce colour to signify positive or negative correlations
- scale the edge thickness to indicate the magnitude of correlation
- scale the size of nodes to indicate which assets have the greatest number of strong correlations with the rest of the assets in the dataset
Remove edges below a threshold
530 edges removed
Create colour, edge thickness and node size features
Draw improved graph
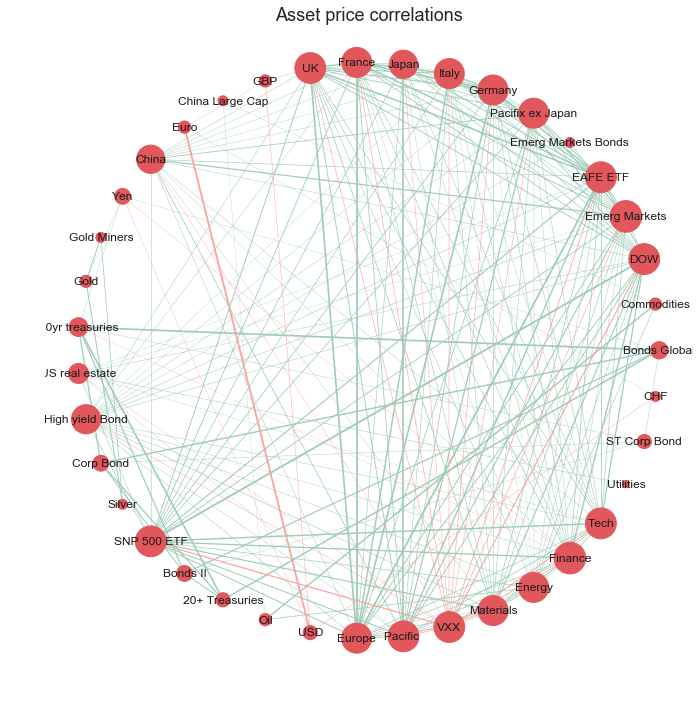
The network visualisation has been improved in four main ways:
- less cluttered: we have removed edges with weak correlations and kept only the edges with significant (actionable) correlations
- identify type of correlation: simple intuitive colour scheme to show positive (green) or negative (red) correlations
- identify strength of correlation: we now are able to assess the relative strength of correlations between nodes, with prominence given to the correlations with the greatest magnitude
- identify the most connected nodes: the size of the nodes has been adjusted to emphasise which nodes have the greatest number of strong correlations with other nodes in the network
Looking at this network we could now quickly identify which assets are highly correlated and therefore may pose increased risk on the portfolio. The viewer could also identify and investigate further the assets with low degree of connectivity (smaller node size) as these are weakly correlated with the other assets in the sample and may provide an opportunity to diversify the portfolio.
The circular layout, however, does not group the nodes in a meaningful order, it just orders the nodes in the order in which they were created, therefore it is difficult to gain insight as to which assets are most similar to each other in terms of correlations to other nodes. We can improve this with a spring based layout using the ‘Fruchterman-Reingold’ algorithm [2] which sets the positions of the nodes using a cost function which minimises the distances between strongly correlated nodes. This algorithm will therefore cluster the nodes which are strongly correlated with each other allowing the viewer to quickly identify groups of assets with similar properties.
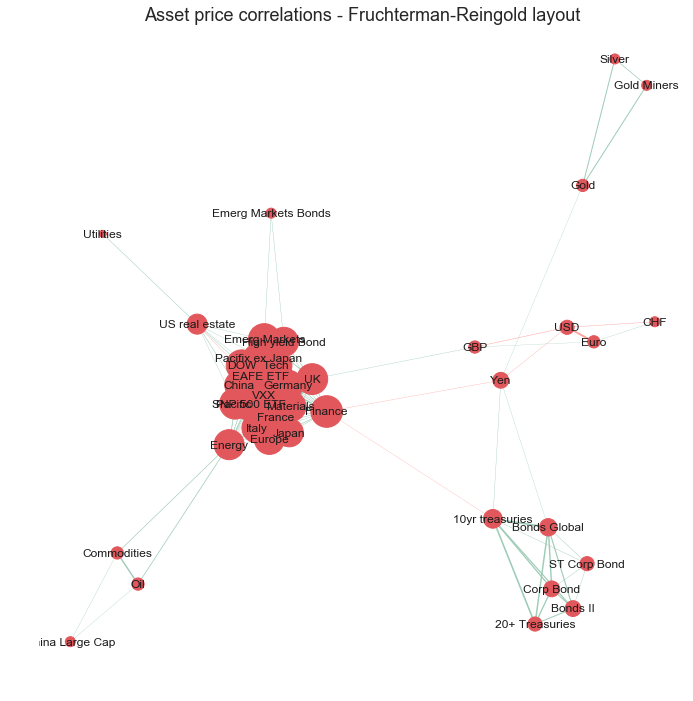
The Fruchterman Reingold layout has successfully grouped the assets into clusters of strongly correlated assets. As seen before in the heatmap visualisation, there are distinct clusters of assets which behave similarly to each other. There is a cluster containing bond ETFs, a cluster of precious metal ETFs (silver, gold, goldminers), a cluster of currencies (CHF, USD, Euro) and a large cluster for equities.
However, the main cluster of equities ETFs is still very cluttered as the nodes are very tightly packed and the node sizes and labels are overlapping making it difficult to make out.
As the layout now positions the nodes which are strongly correlated in space, it is no longer necessary to keep every single edge as it is implied that assets closer to each other in space are more strongly correlated. We can also convert the node sizes back to a consistent (smaller) size as the degree of each node is now meaningless.
Minimum spanning tree
It is common in financial networks to use a minimum spanning tree [3,4,5] to visualise networks. A minimum spanning tree reduces the edges down to a subset of edges which connects all the nodes together, without any cycles and with the minimum possible sum of edge weights (correlation value in this case). This essentially provides a skeleton of the graph, minimising the number of edges and reducing the clutter in the network graph.
Kruskal’s algorithm is used to calculate the minimum spanning tree and is fairly intuitive. However, Networkx has an inbuilt function which calculates the minimum spanning tree for us.
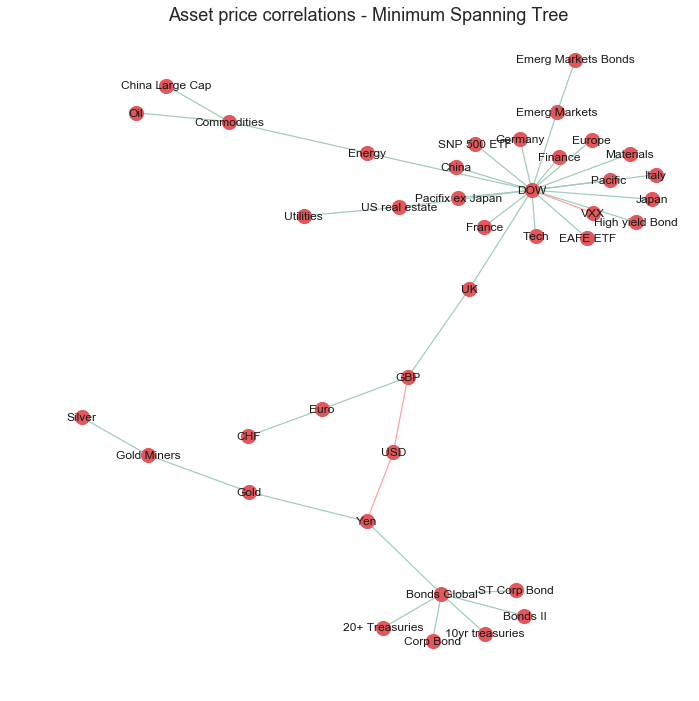
The improved graph has made the clusters of nodes more readable by reducing the node size and reducing the number of edges in the graph. However, reducing the clutter was at the expense of conveying some information about the nodes such as nodes with the most strong correlations and their relative strengths.
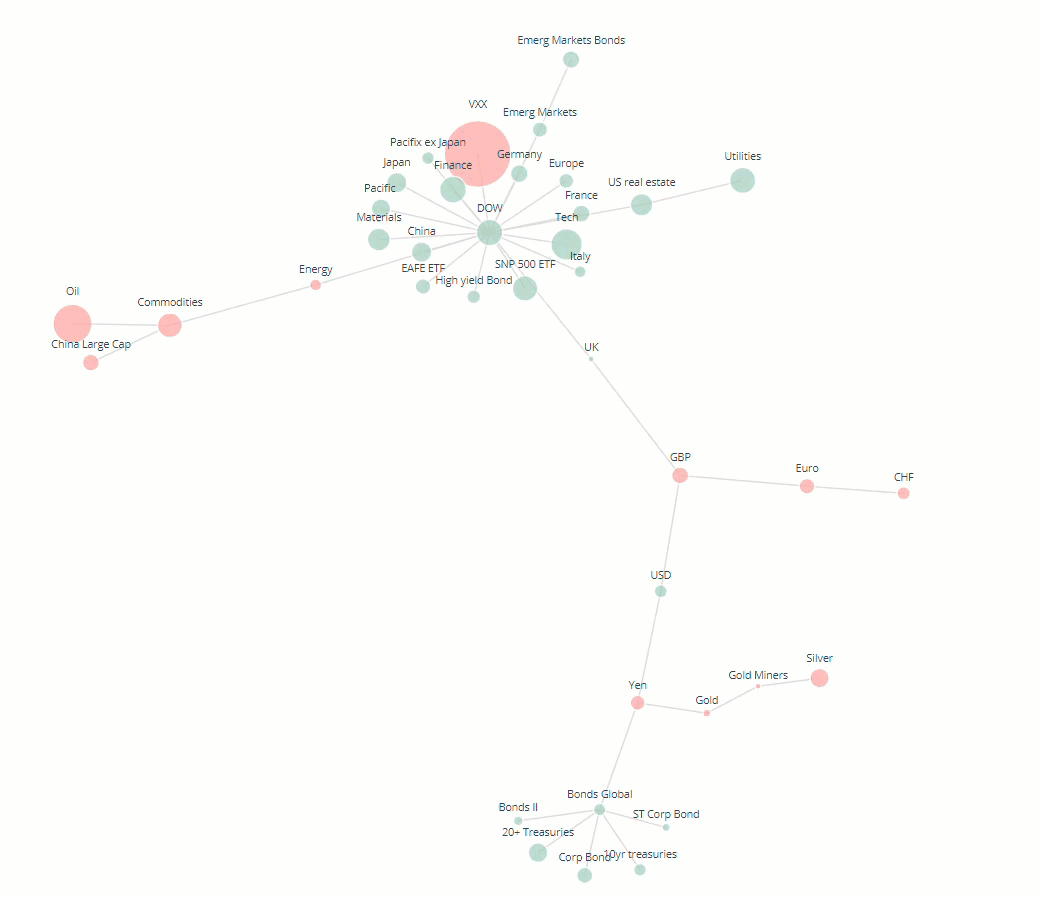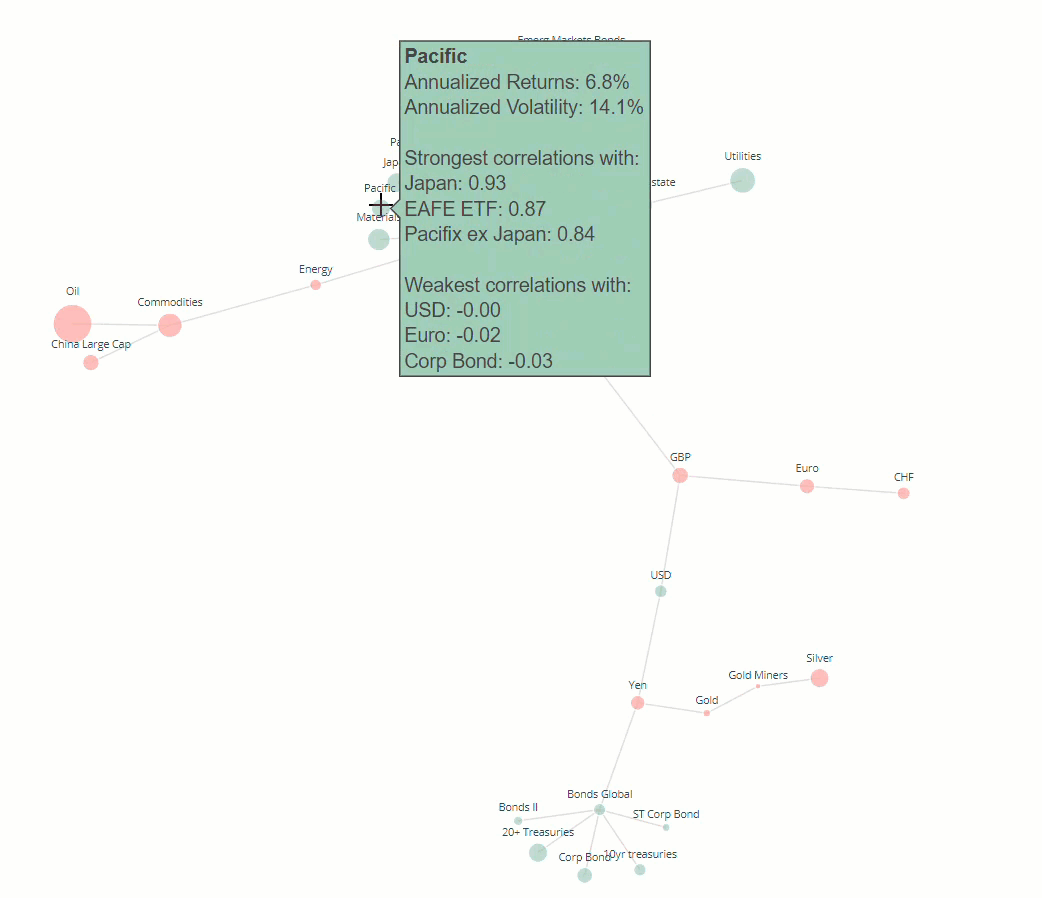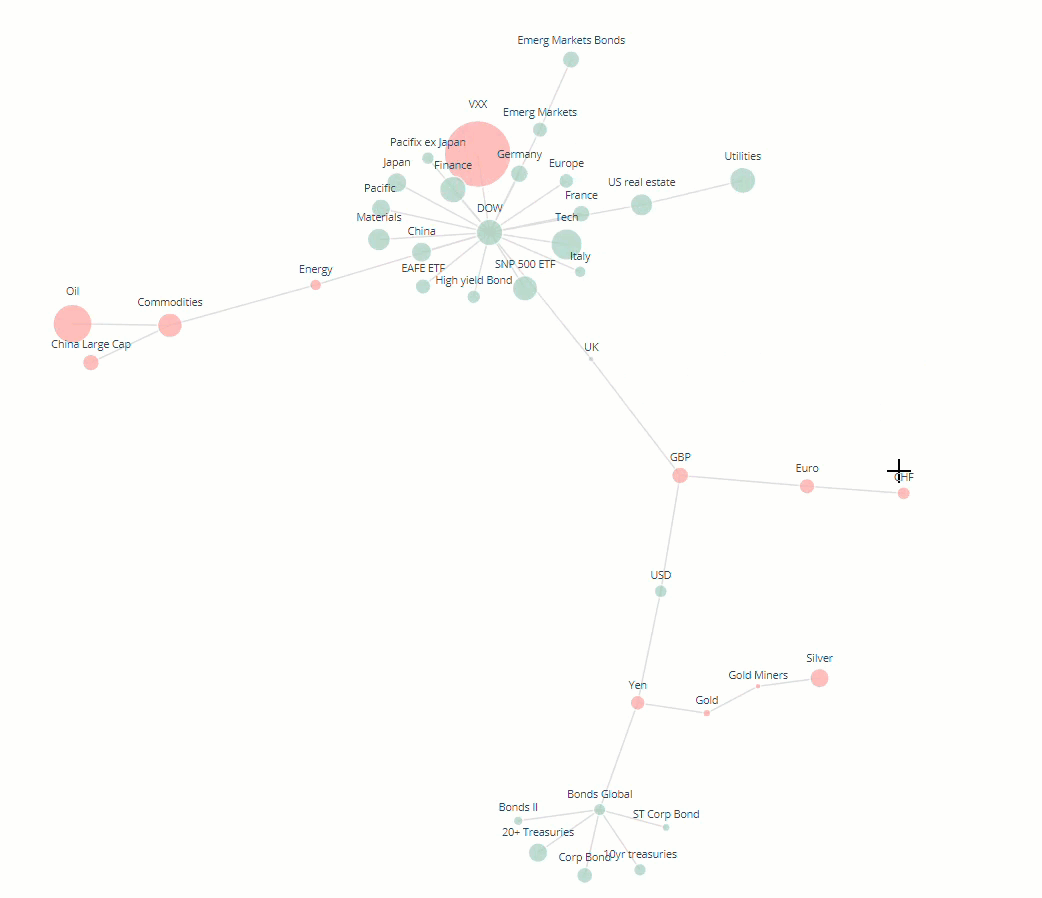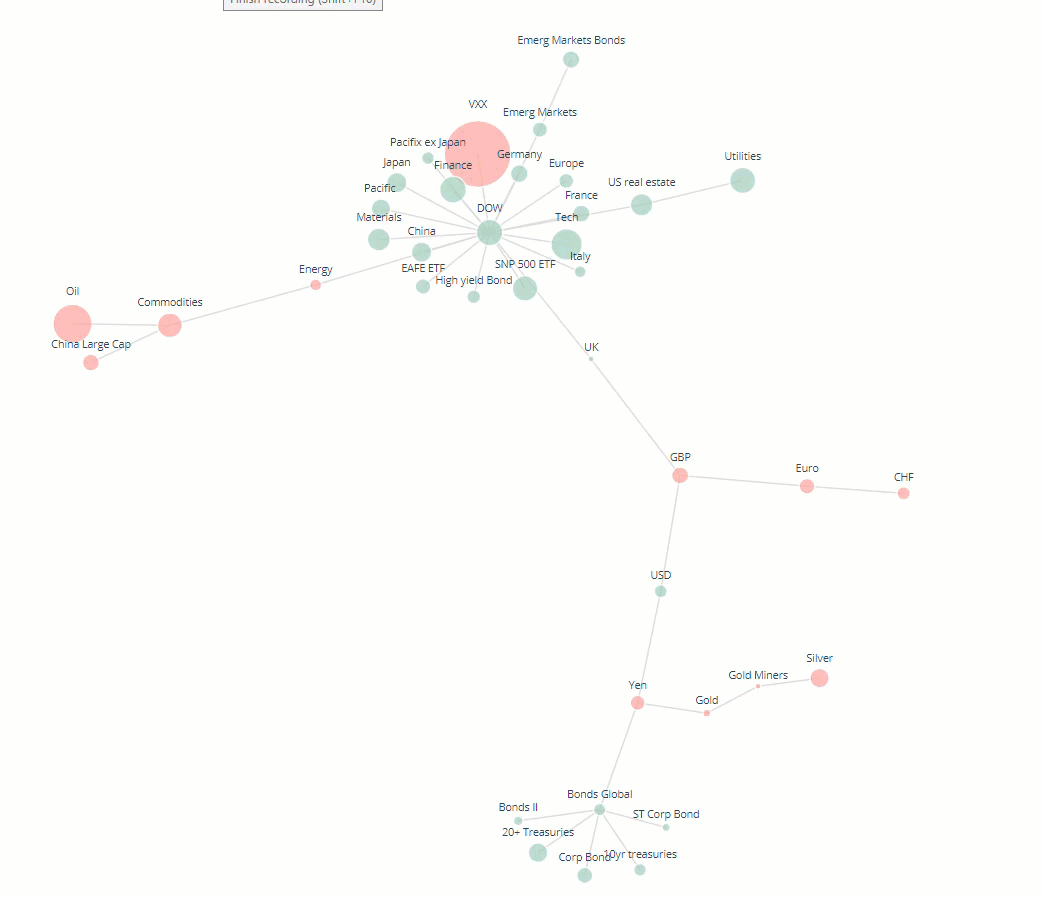
Interactive visualisation
Finally, I will explore the use of interactive plotting libraries to enhance the user experience and alleviate some of the missing information issues with the use of informative tooltips.
Currently the network is very ‘static’ and does not convey any information other than spacial relationships between strongly correlated assets. Although useful, this logically leads the viewer to ask more questions about the properties of each individual node in a cluster such as their historical returns and the nodes with which it is least correlated to.
One way to include such information about each node is to use an interactive graph with informative tooltips. This can be achieved using the Plotly[6] python library which offers a python api to create interactive javascript graphs built in d3.js. The following code uses the Plotly api to create a graph with the following features:
- interactivity, such as zoom, to focus on clusters of nodes
- tooltips which provides useful information about the node when the user hovers over it
- node sizes proportional to the annualised returns of each asset
- node colours to show asset positive or negative return over the dataset timeframe
Plotly
The Python code required for Ploty graphs can be a little bit more involved than out of the box matplotlib or seaborn charts but allows for much more customisation.
The main benefit of using Plotly in this example is the use of tooltips. In these tooltips we can store lots of additional information about each ETF which we can access by hovering over the respective node in the graph.
There are obviously many different bits of information of use which we could incorporate into the tooltip. For this example I will add:
- annualised returns of the asset class
- annualised volatility of the asset class
- the top and bottom 3 assets which the asset of interest is most/least strongly correlated with
Functions to get node information to populate tooltips
The following functions calculate the above quantities. It should be noted that Plotly tooltips are formatted using html. Therefore the input to the tooltip should be a string with the relevant html tags for any formatting that is required.
Function to generate coordinates
Plotly does not have an ‘out-of-the-box’ network graph chart, therefore we need to ‘imitate’ the network layout by plotting the data as a scatter plot which plots the graph nodes, and plot a ‘line’ chart on top which draws the lines which connect each point. To achieve this we need a function which converts the Fruchterman Reingold coordinates calculated using networtx into an x and y series to create the scatter plot. We also need to store the x and y coordinates of the start and end of each edge which will be used to draw the ‘line’ chart.
The function calculates the x and y coordinates for the scatter plot (Xnodes and Ynodes) and the coordinates of the starting and ending positions of the lines connecting nodes (Xedges, Yedges):
Plotly Graph Code
Now we can finally plot the network as an interactive Plotly visualisation.
First, we need to calculate all the quantities and concatenate them into a html string to be used as an input for the tooltip. Then we need to calculate the coordinates for the scatter and line plots and finally define the node color and size which depend on the direction and size of the annualised returns.
To plot the network we define the scatter plot (tracer) and line plot (tracer_marker) series and define some cosmetic parameters which dictate the graph layout.
Node sizes are proportional to the size of annualised returns.
Node colours signify positive or negative returns since beginning of the timeframe.
With this final network layout, we have summarised the most important information about the relationships between assets in the dataset. Users can quickly identify clusters of assets which are strongly correlated with each other, gauge the performance of the asset over the timeframe by looking at the node sizes and colours and can get more detailed information about each node by hovering over it.
Conclusion
In this post we have shown how to visualise a network of asset price correlations using the networkx python library. The ‘out of the box’ networkx visualisations were iteratively improved to help the audience identify assets which behave similarly to other assets in the dataset. This was achieved by reducing redundant information in the network and using intuitive colour schemes, edge thickness and node thickness to convey information in a qualitative way. The functionality of the visualisation was further improved by the use of Plotly, an interactive graphing library, which allowed us to use tooltips to store more information about each node in the network without cluttering the visualisation.
Future Work
Further work could look at the rolling asset correlations over a shorter timeframe and see how these may have changed over time and how this then affects the network layout and clusters. This could help identify outliers or asset classes which are not behaving as ‘normal’. There are also many more interesting calculations which can be carried out on the network, such as working out which are the most important or influential nodes in the networks by using centrality measures [7].
The post focused on how to visualise the network using networkx and Plotly, however, there are many other libraries and software which could have been used and are worth investigating:
Open Source Python Libraries
- Graphviz
- Pygraphviz
Open Source Interactive Libraries
- d3.js
Network drawing Software
- Gelphi Gelphi (https://gephi.org/)
If you are interested in investigating network analytics in the financial industry in more detail, I would highly recommend checking out FNA which is a commercial platform for financial network analytics. They have a free trial to their platform which has some very impressive network visualisations of the stock market but also financial transcations for fraud detection and many more applications.
References
[1] Networkx documentation: https://networkx.github.io/documentation/stable/reference/drawing.html
[2] Fruchterman, T.M. and Reingold, E.M., 1991. Graph drawing by force-directed placement. 1991. Zitiert auf den, p.37.
[3] Mantegna, R.N., 1999. Hierarchical structure in financial markets. The European Physical Journal B-Condensed Matter and Complex Systems, 11(1), pp.193-197.
[4] Rešovský, M., Horváth, D., Gazda, V. and Siničáková, M., 2013. Minimum Spanning Tree Application in the Currency Market. Biatec, 21(7), pp.21-23.
[5] Financial Network Analytics: https://www.fna.fi/
[6] Plotly: https://plot.ly/d3-js-for-python-and-pandas-charts/
[7] Wenyue Sun, Chuan Tian, Guang Yang, 2015, Network Analysis of the Stock Market
Comments